上一篇文章给大家介绍了如何使用 Thrinax 抽取网站正文页信息。在实际使用中,新闻类网站基本遵循 “首页>频道>正文” 的页面模式,识别频道页(列表页)成为了获得信息的基础,今天给大家带来该系列的第二篇,基于模式识别的网站列表页信息抽取。
Thrinax 提供 .Net 4.5 以上,.netcore 2.0 以及后续版本的支持;使用较低版本的用户只能自行通过源码编译,或者升级 .Net 的版本。目前在 Nuget 发布的版本属于测试版本,在未经详细测试验证前,请勿用于生产环境,在版本号小于 2.0 之前,不对版本的兼容性做保证。
今天要介绍的功能为:网站列表页模式识别。该方法的基本思想为通过获取网站上所有包含 Url 的 a 标签,识别其 Xpath,然后合并相似的同级元素,对每一种 Xpath 归纳出基础 Xpath,然后从它的子节点获取各种字段,枚举组合后给打分函数计算出最可能的几种方案供用户审核。
要使用该方法首先需要通过 Nuget 安装 Thrinax:
PM> Install-Package Thrinax
然后使用以下方法获取列表页的网页内容,为了支持某些后加载的网站,这里也提供了基于 Selenium chrome 的访问模式。
HttpResult httpResult = null;
if (UseBrowser)
httpResult = SeleniumHelper.HttpRequest(channelUrl);
else
httpResult = HttpHelper.HttpRequest(channelUrl);
需要注意的是使用浏览器版本的必须要在执行的机器上安装有 Chrome 浏览器。
然后调用模式识别函数获取可供选择的多个模式(带有得分):
var listPagePatterns = SmartParser.Extract_Patterns(channelUrl, httpResult.Content, MediaType.WebNews, Enums.Language.CHINESE);
实际可供大家直接测试效果的 demo 也已上传到 GitHub 中,使用到了 WPF,暂时仅支持在 Windows 环境下运行,下面是运行截图:
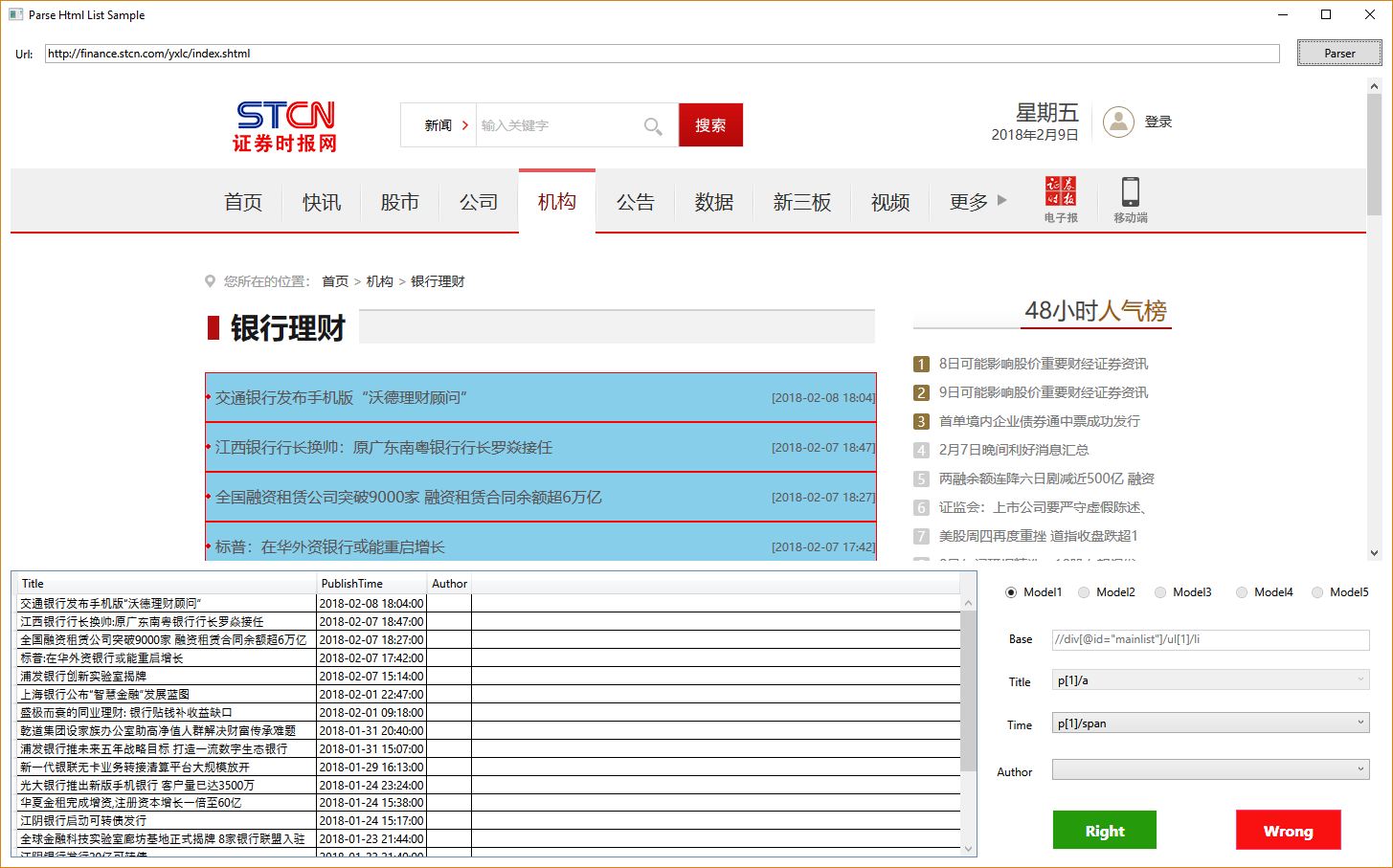
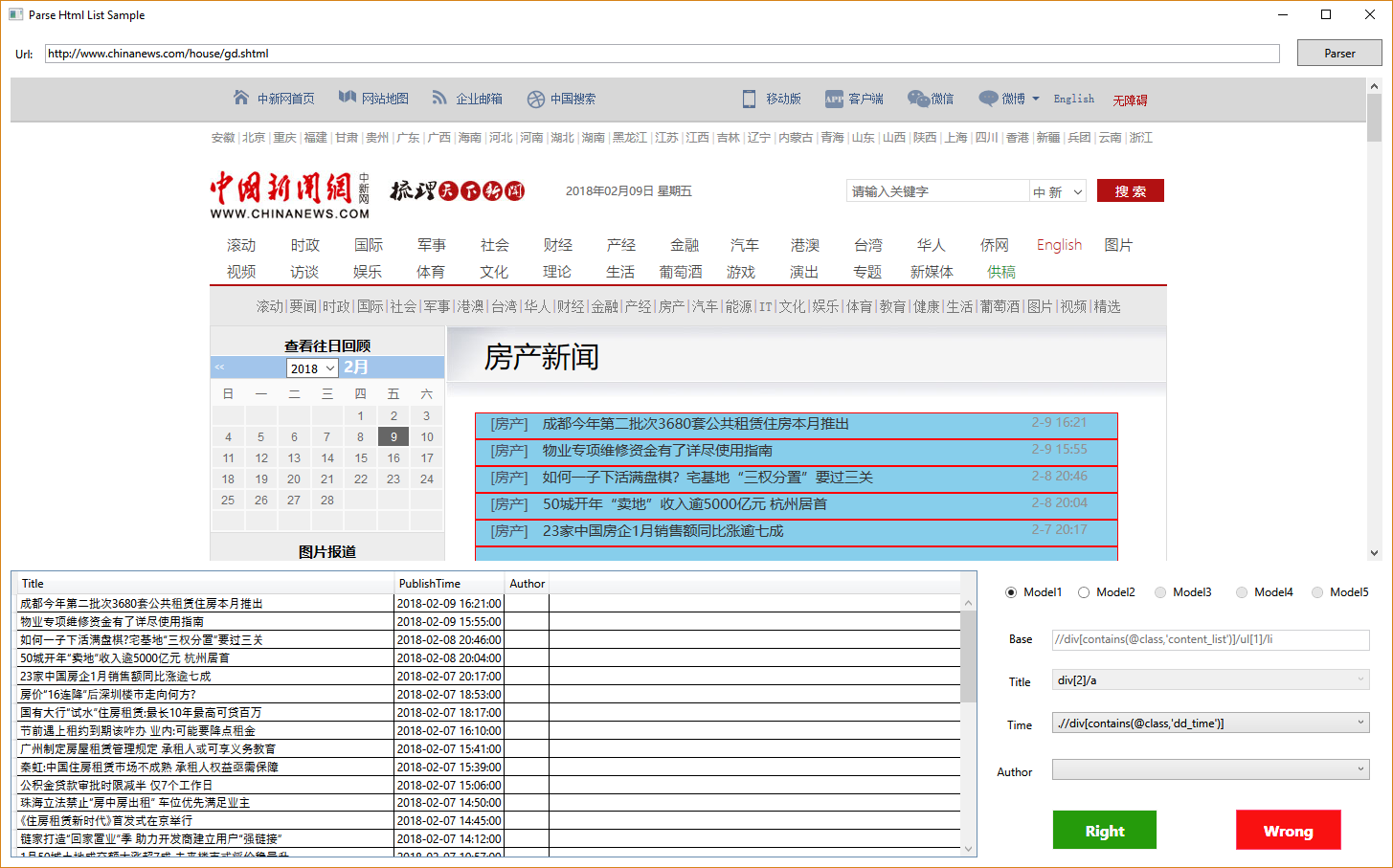
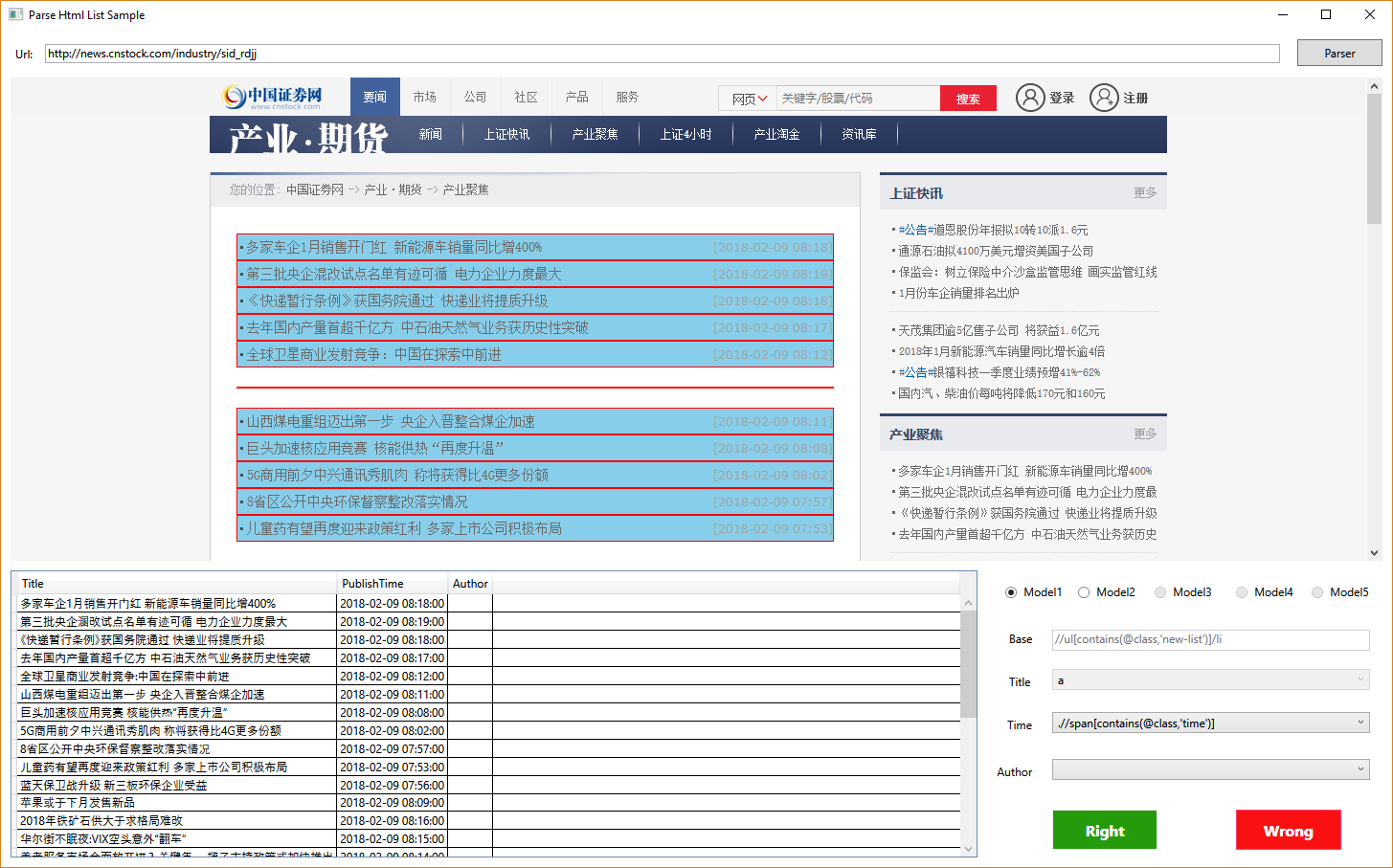
这个版本仍然是一个测试版本,代码会较为频繁更新,如果本文描述与源码表现出现出入,以 GitHub 上的版本为准。接下来的文章将介绍如何通过列表页来实现对信息抽取准确度的提高,以及网站翻页的处理。
最后,如果对这个项目感兴趣的话,快到 GitHub 上 Star 和 Fork 吧,也欢迎大家一起来贡献代码;当然,如果你是爬虫工程师或者对爬虫非常感兴趣的话,最好的方式是把简历投递给我,期待能一起共事!
本文来自 The NewIdea,作者 Carey Tzou 。
永久地址:https://www.tnidea.com/new-netcore-page-list-extract-lib-thrinax.html
未经授权,拒绝任何全文及摘要转载!