好久不见,这次给大家带来一个全新的基于 .Net 的中文网页信息抽取的类库,Thrinax。该库的目标是通过一种简单的,低人工参与的方式来实现稳定的获取网页中的有效信息;这将会是一个系列文章,在书写文章的同时,类库也会不断完善,今天带来第一篇,基于网页区块的详情页信息抽取。
Thrinax 提供 .Net 4.5 以上,.netcore 2.0 以及后续版本的支持;使用较低版本的用户只能自行通过源码编译,或者升级 .Net 的版本。目前在 Nuget 发布的版本属于测试版本,在未经详细测试验证前,请勿用于生产环境,在版本号小于 2.0 之前,不对版本的兼容性做保证。
今天要介绍的功能为:文章详情页抽取。该源码借鉴了 stanzhai 的 Html2Article的思想,原方法使用文章的分行字数作为判断依据,获取字数较为集中的部分作为文章的正文。在 Apache 2.0 协议下开源,在此感谢他的付出。
Thrinax 中的 HtmlToArticle 位于 Thrinax.Extract 下,使用前先通过:
PM> Install-Package Thrinax
安装 Thrinax 类库,使用以下方法调用。
Article article = HtmlToArticle.GetArticle(htmlContent);
需要注意的是该版本与原有的版本字段不再兼容,下面介绍改进的几个方面:
使用div标签替换原有的按换行符的分段方式,并对所有div标签进行打分,规避了之前的遍历深度难以界定的问题,减少了正文出现遗漏或者杂质的概率;
为了选出最合适的区块,打分函数考虑了内含标签,字数等各种情况,根据数百个媒体的实际情况对参数进行了优化;
针对特殊的容易混淆的区块,还支持排除词的得分衰减,同时考虑了部分网站布局不清晰时使用段内的P标签的内容;
重写了时间识别的函数,将识别的准确性大幅提升;
标题仍然采用了原有的h1与title获取的方式,修改了一些可能出现的BUG,由于一般列表页已经获取到标题,所以此处不是特别重要;
媒体什么的非必要字段暂时未实现。
下面放几张实际解析的效果图片吧:
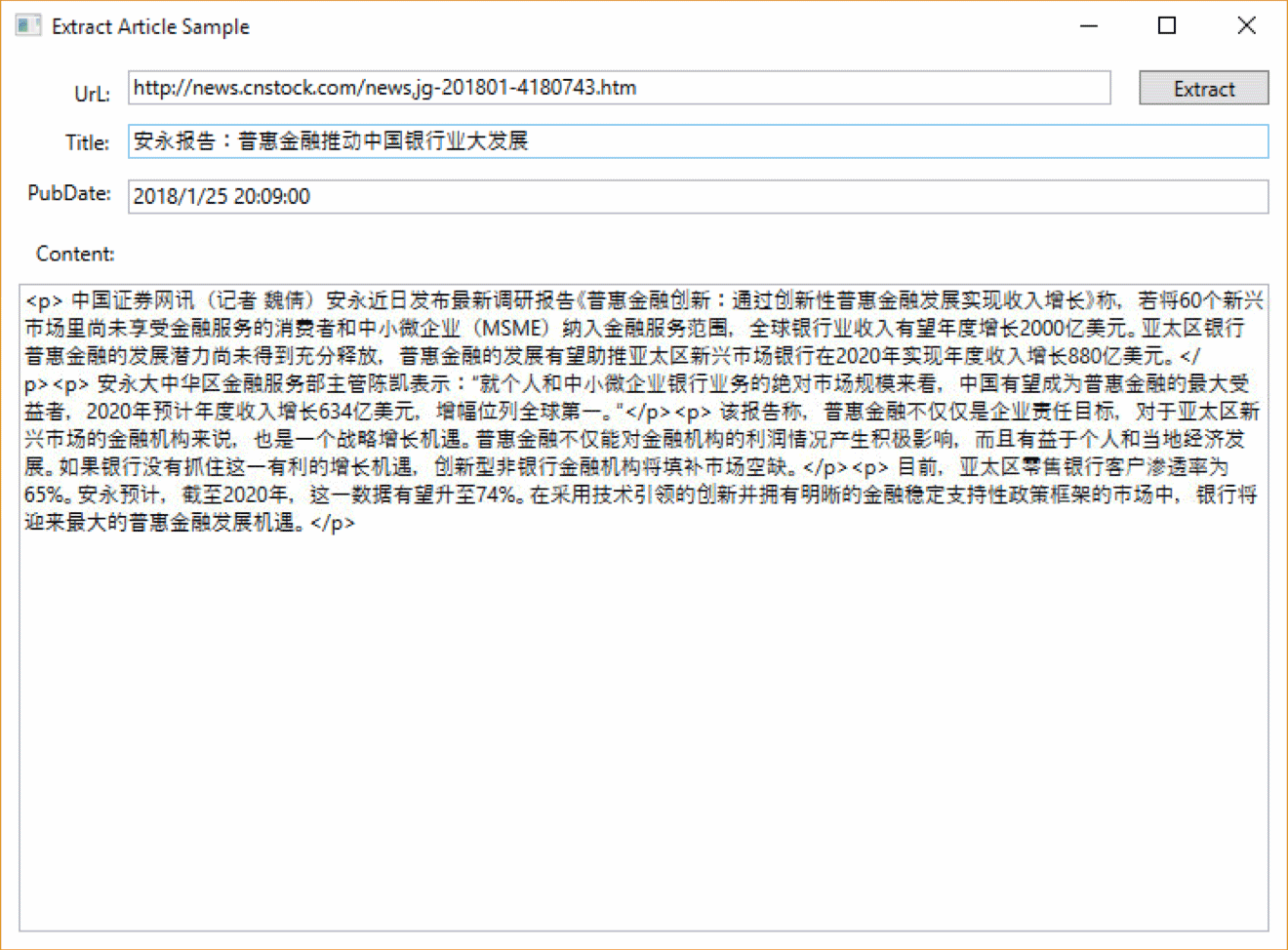
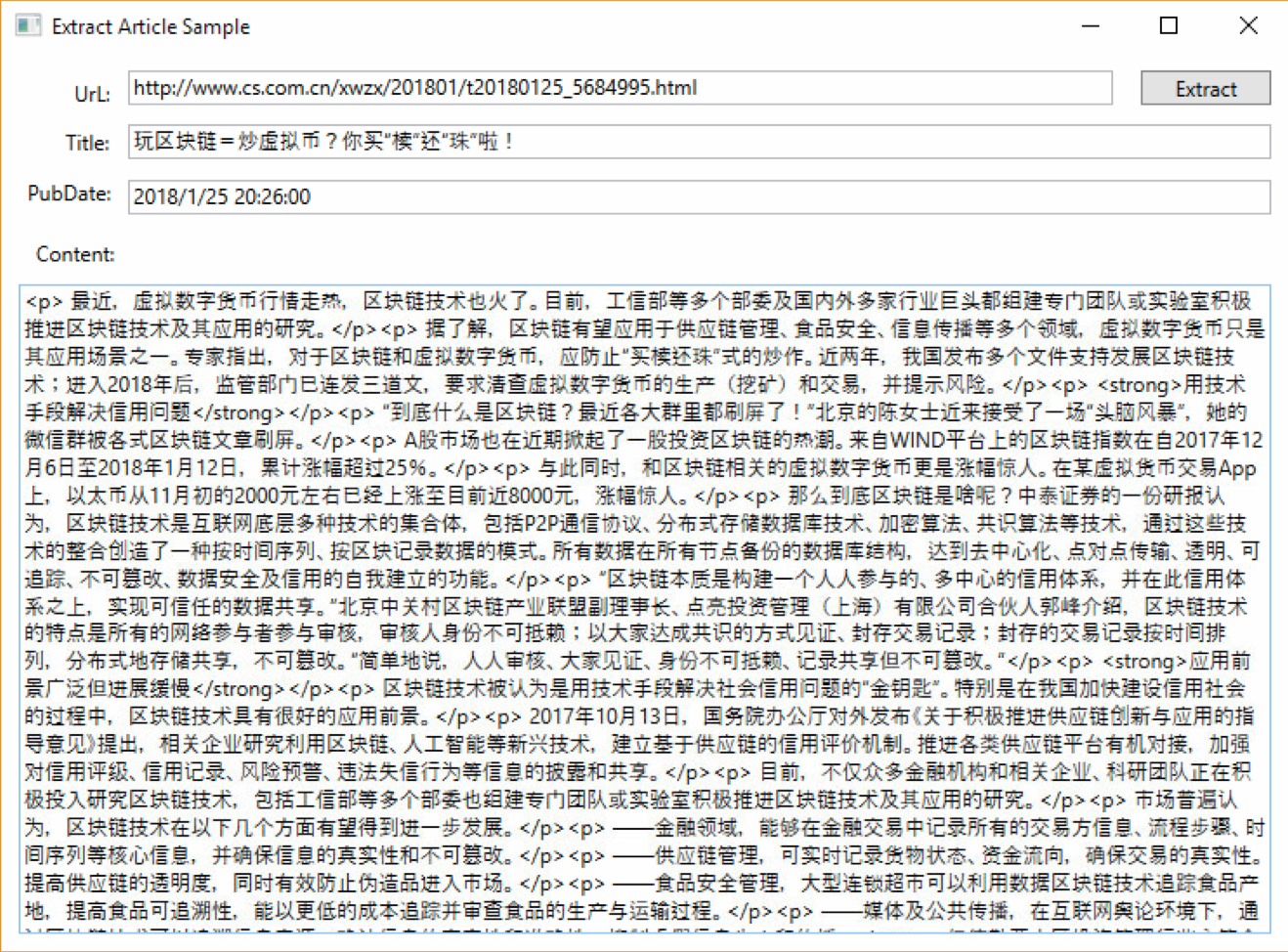
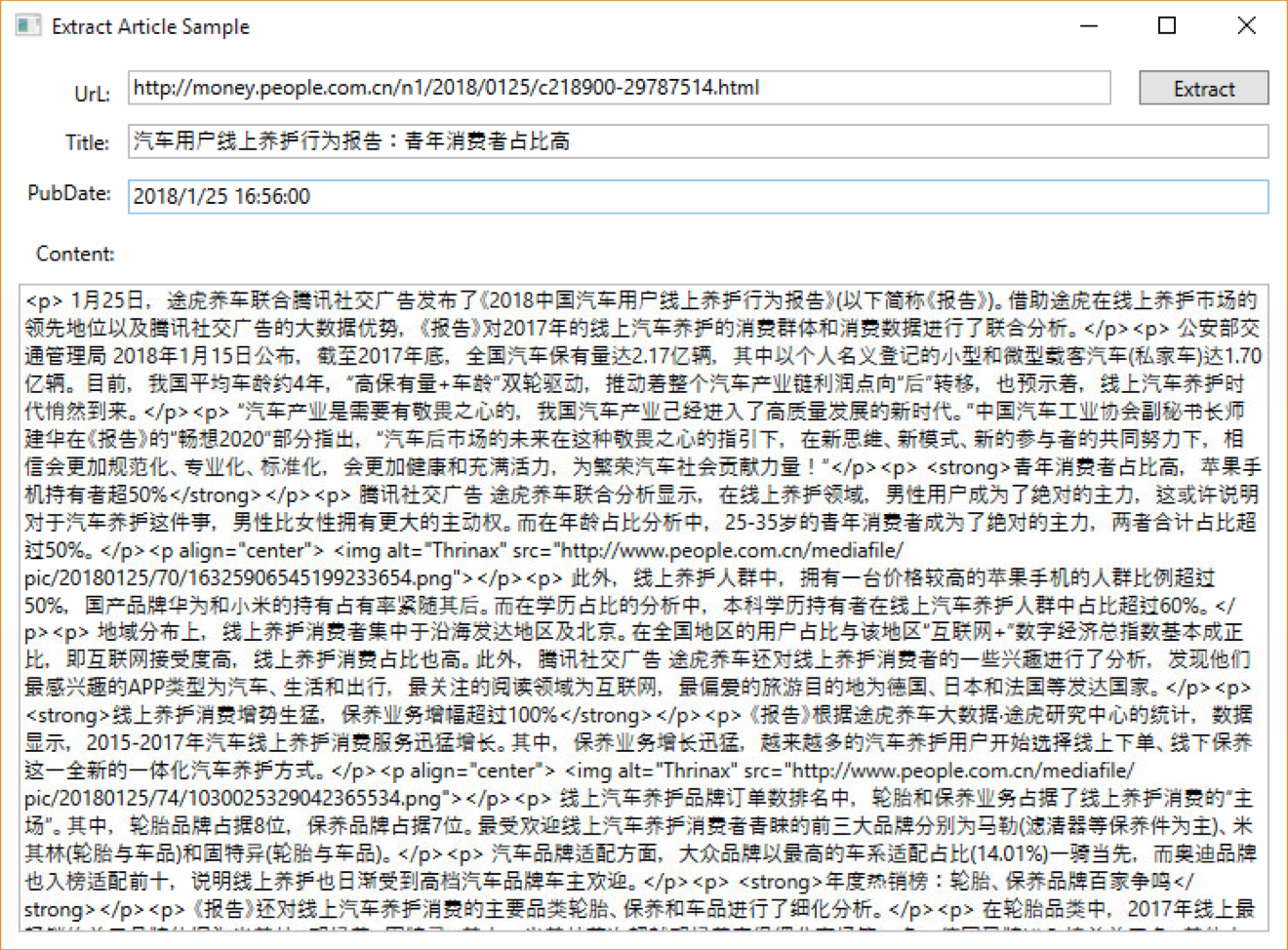
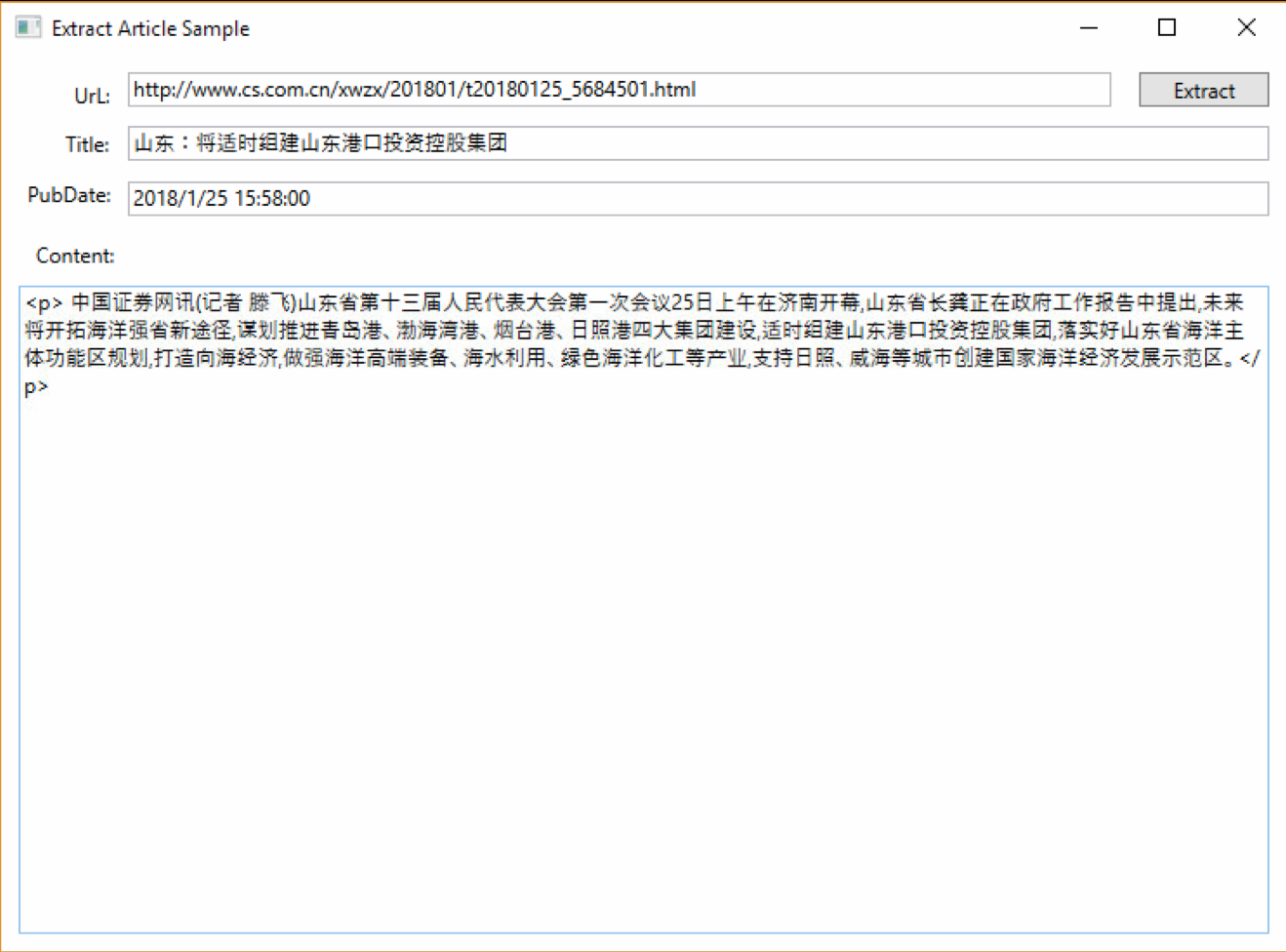
这个版本仍然是一个测试版本,下一篇文章会写列表页的解析,列表页相对文章页难度更大,需要配合一定的人工的工作,同时由于一个列表页可以解析出多篇文章的Url,所以相应的会给文章页解析带来新的思路,能大幅减少出现错误的概率。接下来会实现翻页的逻辑,在文章页和列表页都会十分有用,时间待定,期待吧!
最后,如果对这个项目感兴趣的话,快到 GitHub 上 Star 和 Fork 吧,也欢迎大家一起来贡献代码;当然,如果你是爬虫工程师或者对爬虫非常感兴趣的话,最好的方式是把简历投递给我,期待能一起共事!
本文来自 The NewIdea,作者 Carey Tzou 。
永久地址:https://www.tnidea.com/new-netcore-unstructured-text-capture-lib-thrinax.html
未经授权,拒绝任何全文及摘要转载!